语义网的软件工程数据查询处理技术论文
2019-11-20 21:00:01 131
摘要:在新时代的背景下,科学技术的发展速度明显加快。通过对语义网的深入研究,可以为研究人员提供有价值的参考。在此基础上,作者以语义网为研究重点,阐述了基于语义网的软件工程数据查询处理技术,以促进软件工程的发展。
关键字:语义网;软件工程;数据查询;处理技术
在开发软件系统的过程中生成的数据非常复杂且语义丰富。如果需要以统一的方式管理不同类型的软件工程项目数据,则必须构建一个灵活的语义模型。管理软件工程数据对于不断提高实际查询的效率具有一定的现实意义。语义Web技术的飞速发展为解决上述问题提供了必要的解决方案和途径。有必要深入研究基于语义网的软件工程数据查询处理技术。
1语义Web概述
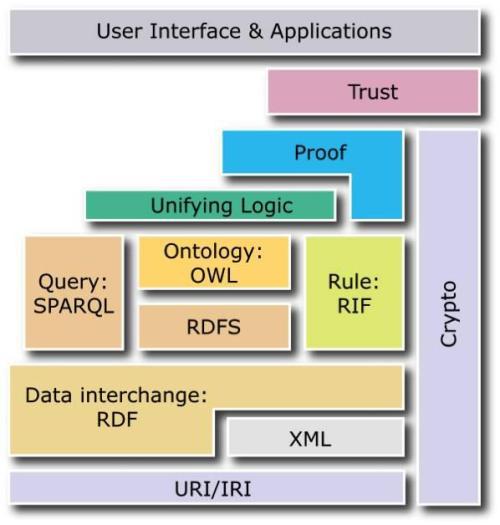
所谓的语义Web是指使用计算机作为重要参考依据,有效连接网络资源,然后描述网络数据结构或增加元数据的路径。在上述过程中,可以实现语义信息的有效交换,并且可以有效地管理数据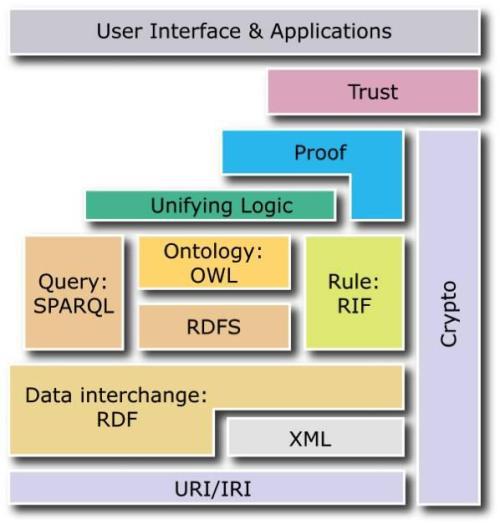 。在当前阶段,语义网的定义尚不清楚。通常,语义Web是与W3C相关的技术标准和模型,主要集中在网络本体语言,资源描述框架和定义本体上。在这种情况下,在软件工程处理方面,语义网的合理应用已逐渐成为未来发展中亟待解决的问题。
。在当前阶段,语义网的定义尚不清楚。通常,语义Web是与W3C相关的技术标准和模型,主要集中在网络本体语言,资源描述框架和定义本体上。在这种情况下,在软件工程处理方面,语义网的合理应用已逐渐成为未来发展中亟待解决的问题。
2软件工程数据本体模型解释
2.1源代码
源代码在软件开发中起着核心作用,在通常情况下,软件开发语言很多,而面向对象的语言是核心模型。其中,存在面向对象语言的三个特征,即继承,多态和封装。在此基础上,面向对象语言的语言元素也涵盖了调用和包含等相关链接。实际上,语言特征主要通过以下关系来表达。
(1)列入。一个包中包含不少于一个的类。
(2)继承。类与类之间存在继承关系。
(3)多态性。在子类之间,实现差异是相对于父类方法的。
(4)通话。在类中的特定定义方法或其他类定义方法的调用中,方法之间存在某些调用关系。
(5)软件包。具体来说,是类中的成员访问的权限。源代码模型并未涵盖所有代码信息。主要原因是信息构建模型将有效地扩展查询应用。但是,在存储和检索信息的过程中,尤其是在数据量很大的情况下,实际情况需要花费时间和空间来连接公认。因此,即使模型丢失了部分信息,也可以确保存储效率和查询效率满足标准和要求
。
2.2需求
构建需求本体的单个数据,其主要目的是分析软件并实现代码重用。在本体模型中,本体建模是通过组合用户和特定于功能的需求数据来完成的。通常,系统涵盖大量模块,每个模块包含更多的用户需求,或者每个功能具有多个子功能,但不考虑非功能需求。主要原因是很难将代码结构真正体现出来。可以看出,需求本体模型可以细化为两类,即需求模块和需求用例。其中,不同级别的需求名称,后置条件和前提条件通过数据属性形式反映在类中。在分离模块和用例方面,主要目的是确保模型更分层并且更易于理解,以便它可以对应于源代码模型中类的每个级别。
2.3测试
对于测试本体模型,主要模型基于系统测试。其中,系统测试需要与实际需求规范相结合,编写测试用例,并在需求规范的内容中涵盖每个模块或每个功能的需求用例和子功能
。由于不考虑非功能测试,因此可以将系统测试完善为模块化或功能测试。在此基础上,模块测试和功能测试的组成具体包括用例测试和子功能测试。每个用例测试和子功能测试也可以细分为一些测试用例部分。测试用例具有优先级,预期结果,用例描述,测试预设条件,用例编号和测试步骤。对于上述许多数据属性,单个测试用例将在执行后形成相应的执行结果。
2.4缺陷
在正常情况下,测试人员或其他项目人员发现系统和软件缺陷后,缺陷信息将通过缺陷跟踪系统提交,并且系统将合并Submit信息,将任务分配给适当的开发人员,然后完成修改。当开发人员完成修改后,需要在缺陷跟踪系统中修改缺陷的状态。此时,发布者可以查看已修改的缺陷,并且参与者还可以对缺陷进行评论。缺陷跟踪系统是不同的,其内部功能也有很大不同,但是它们也具有相同的特征。系统用户不仅可以发布缺陷,还可以起到修改和注释缺陷的作用。缺陷还具有各种预制的相对名称,其类型,特定描述,优先级和相应的系统版本。提交缺陷报告时,应通过附件说明缺陷。
版本2.5
在软件开发中,软件版本信息不可忽略,它是重要的数据之一。通过软件版本,从软件开发到软件发行的整个过程都可以反映为软件维度。保护提供了宝贵的参考。在此阶段,需要通过基于版本的软件来管理版本信息。相应的数据存储在源代码数据,需求数据以及测试和缺陷数据中,因此抽象非常明显。可以看出,版本信息应被理解为其他软件工程数据版本的索引。
2.6数据和数据关联
通过以上对软件工程数据五类特征的研究,构建了相应的本体模型。由于模型彼此独立,因此它们只能反映软件。项目的某些方面。为了对软件进行全面的系统分析,有必要实现上述模型的有效关联,以确保根据一种数据类型搜索另一种类型的数据,以达到数据管理的目的。在版本系统控制方面,不仅可以控制和管理源代码更改,还可以控制和管理其他文档。对于软件生命周期,源代码类的版本很多,模块需求数据和测试数据的版本也不同,并存储在版本控制系统中。
3软件工程数据的开发
在软件工程系统的深入开发过程中,很容易形成海量数据信息。需要说明的是,系统本身的结构非常复杂,语义丰富,可以统一管理数据信息。在这种情况下,实施软件工程时会遇到许多问题和不足。在开发传统软件时,在软件工程处理中需要大量的人力资源,因此大量消耗了人力和财力。此外,软件的开发,尤其是存储软件工程的特殊位置,仍然使用应用程序文件方法,因此存储部分分散。在这种情况下,不允许使用语义方法检索,管理和存储数据信息作为参考。从长远来看,数据与数据之间的相关性会丢失。在软件工程中引入数据挖掘技术可以有效提高整体质量水平。以软件工程操作为例,对跟踪缺陷的研究需要灵活使用自动异常检测算法,这严重忽略了整体性能。在实际实施语义Web软件工程的过程中,研究人员没有引入测试数据和需求数据,因此管理和开发项目人员很难获得必要的帮助。一般来说,查询处理软件工程技术的应用也存在一定的缺陷和问题,因此在以后的研究中有必要采取必要的改进策略。
4基于语义Web的软件工程数据查询处理技术
通过对语义Web内容的分析,我们可以理解,通过应用本体语言和本体,我们可以描述复杂的数据信息并充分展示其建模能力,以确保软件工程项目的数据结构特征可以相互关联。基于此,在语义网的前提下,查询处理软件工程的科学应用和基本的数据统计功能可以实现查询信息流程的进一步优化。标准。基于上述方法,可以避免在数据查询过程中出现操作错误,并有效地加快了争议查询的速度。其中,语义网络是本体数据查询的组成部分,为软件工程项目的开发提供了必要的保证。
4.1查询要求
一般来说,结合每个软件工程项目的特定要求,可以对软件工程数据进行完善以执行关键字查询,相似性查询和相关性查询。其中,关键字查询是使用最广泛的查询方法,即通过在相应的输入区域中输入相应的关键字符,可以找到满足特定需求的文章。在语义Web环境中,在查询关键字的过程中,关键字的查询要求最大路径小于2星的长度。在相似性查询的情况下,软件的深入开发需要大量代码。在这种情况下,很容易拥有与其他代码相似的代码结构。但是,由于上述代码不需要很高的名称,因此应考虑和分析具体情况,以确保功能和结构得到有效固定
。可以看出,类似于变量查询方法,相似度查询可以通过相似图获得信息相似度。4.2本体模型
为了全面描述实际数据信息,有必要确保需求数据,版本数据,源代码数据和测试数据具有相应的版本模型,这些模型可以与数据结合。数据模型的相关性可以实现有效的连接。源代码在开发软件中占据着中心位置,并且开发语言具有多种特征。通过分析软件需求和代码重用本体个体数据的构建,在构建本体数据模型的过程中,应将本体建模作为重要的参考依据,以确保其满足用户的实际需求并充分发挥功能的作用。 。
5结论
总之,通过对语义网的进一步研究和分析,它可以为查询处理软件工程的全面发展提供新的思路。以语义网为核心,对软件系统进行分析,使网络本体语言能够描述复杂的事物,科学合理地构建数据模型,为软件工程的合理化提供保证。在实践过程中,语义Web数据模型的描述更加清晰直观,在有效地展示软件工程语义网络处理数据功能的同时,有必要构建一个本体模型来实现软件工程创新发展。
参考文献
 陈伟。姜建国,。建华。基于语义网的软件工程数据查询处理技术[J]。电子技术与软件工程,2015(4):198。
陈伟。姜建国,。建华。基于语义网的软件工程数据查询处理技术[J]。电子技术与软件工程,2015(4):198。
姚玉凡。语义网软件工程数据查询处理技术研究与分析[J]。信息系统工程,2016(3):90。
王秀明.WinCC自定义数据库的数据查询和报表生成分析[J]。科技术经济指南,2015(5):99-100。
周小龙,刘芙蓉,范敏仪。 WinCC定制数据库的数据查询和报表生成[J]。工业控制计算机,2013(4):22-23。
张成才。证券交易数据查询系统的设计与实现[D]。厦门:厦门大学,2012年。
曹菊义。基于语义网的软件工程数据查询处理技术研究[D]。上海:华东师范大学,2011年。








